The naive plug-in estimate is fairly straightforward. We start with the data (which is IID from ) and we use some kind of algorithm to come up with a guess for the probability distribution that generates it. We call that guess . We then evaluate our parameter at to get the estimate. In other words, we define .
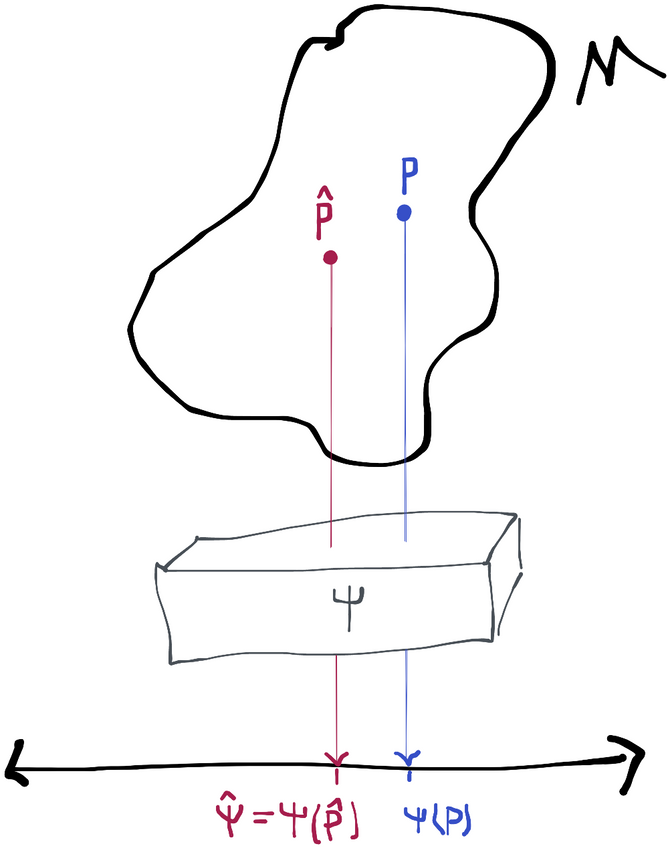
Recall that the efficient influence function (and influence functions in general) depend on what point we're at in the statistical model . We don't know so we don't know the efficient influence function for , which is . However, we do know so we can use the techniques from the previous chapter to find its influence function , or for short.
Example: ATE for Observational Study
For example, let's work with the data structure that we'd find in an observational study and assume that our parameter of interest is the average treatment effect . As before, we'll notate so we can also write the target parameter as . For simplicity let's assume the outcome is binary.
We need to use the data to come up with an estimate of the joint distribution. We can break that down by factoring and coming up with estimates for each factor. For example, maybe we use the empirical distribution of as our estimate . We might also use a probabilistic classification algorithm (e.g. random forest) trained by regressing onto to estimate the probability of treatment and the same algorithm trained by regressing onto to estimate the probability of an outcome .
Now we just need to apply the definition but take the expectations with respect to our estimate instead of the unknown . Based on the estimates we defined above, and the definition of our parameter we get
Or, in words: take the sample average value of our estimate for the treatment outcome and subtract off the sample average value of our estimate for the control outcome. You might think of this as "imputing" the expected probability of the outcome under each treatment, for each subject in the study, and then averaging and taking the difference.
Asymptotic Analysis
A naive plug-in estimator is nice because it's easy to understand and construct, but since we haven't said anything about what kind of algorithm we use to estimate we can't ensure that the plug-in will behave nicely. As a stupid example, consider that we use some algorithm that completely ignores the data and always returns some fixed distribution . The plug-in estimate based on that distribution will always be the same number so this estimator won't have a normal sampling distribution. Nor will it be centered at the true parameter unless we get lucky and .
Our goal, therefore, is to come up with some "rules" that our estimator for has to follow in order to make the plug-in estimator asymptotically linear with the efficient influence function:
Notation:
Often in asymptotic statistics we want to say something like " where ". This is kind of annoying to write, so instead you'll more often see . You can read the term as "some sequence of random variables that converges in probability to 0". The benefit of this is that we don't even have to give this sequence a name (like , for example) if we don't care to. Moreover, we've hidden away any limit arrows and are left with an equation that we can manipulate algebraically.
This notation is extended to handle cases where we want to say " where ". The abbreviation for this is . The way I think of this is that , so we divide by to get . The last equality here defines what we mean when we say some variable is : namely that times converges in probability to 0. When this is the case we say that " converges at the rate ".
For example, in our definition of the influence function we had that . If we let , then this just says , which we can write as . Now, spelling out gives us the alternative definition .
The intuition for "rates" is that often we're interested in random variables that go to 0 so quickly that even if they get blown up by some increasing sequence, the product still goes to 0. For example, if some variable is , that means that still goes to 0, even though is an increasing sequence that gets bigger and bigger.
Understanding this about rates also shows that anything that is is also , but not the other way around, and similar facts of that nature. That's because something that converges to 0 even if it's blown up by must go to 0 (even faster) if left alone.
You can learn more about this notation in chapter 2 of vdW98 and in a number of online resources (google "little oP" or "little oh p"). A through understanding requires a grasp of convergence in probability (see the recommended resources to learn more).
From here on I'm going to use and interchangeably with and to keep things uncluttered when necessary. I'll also omit the dagger () as a superscript of the efficient influence function, since from here on out we won't be talking about any influence functions that aren't efficient.
We want to get an idea of the magnitude of the estimation error . We actually have a pretty nice way to do this if we construct a path from to and then use the pathwise derivative along this path, exploiting the fact that we know how to express the pathwise derivative at 0 as the covariance between the path's direction (the score ) and the canonical gradient of the parameter at (which is the efficient influence function ). To wit:
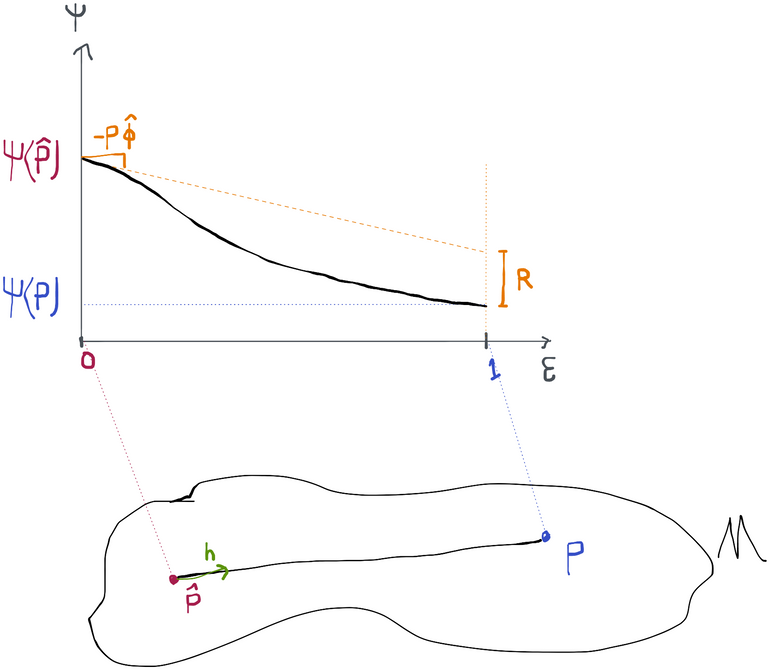
In this case . The equality in the last line is because by the definition of the score along a path from to and the change-of-variables formula.
This is called the von Mises expansion of our estimate, which is a lot like the first-order Taylor expansion you may have seen in calculus. The idea is to use a derivative at a point and the value at that point to estimate the value of the function at a nearby point. It is an approximation, however. Because we let be some finite value, the linear approximation won't be perfectly accurate. We'll call the approximation error , so we have that .
This gets us a little closer to where we want to go. Starting from here, we can add and subtract , , and to the right-hand side and rearrange terms to get
Now we're good. Comparing this to the characterization of an efficient estimator we see that for our estimator to be efficient, the sum of the three terms after the "efficient central limit theorem (CLT) term" needs to be to make the two characterizations match up. This will be the case if each of the three terms is , so that's what we need to show. We'll give each of these terms names and get to know them more intimately one-by-one:
Plug-In Bias:
Empirical Process:
Second-Order Remainder:
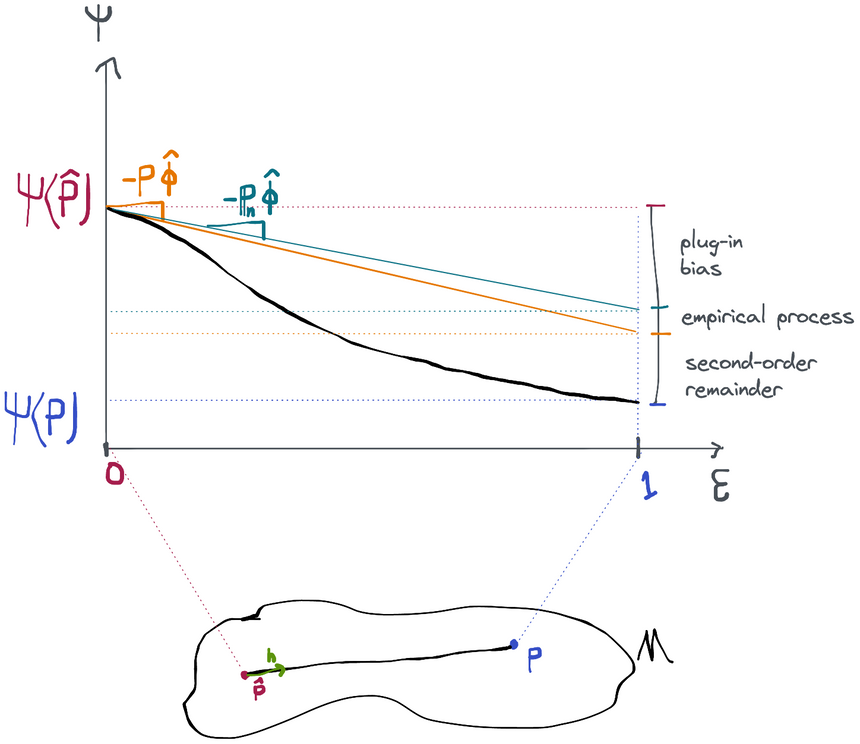
Plug-In Bias
The term is known as the plug-in bias term because, in general, it's not possible to show that it goes to zero at all for a generic plug-in estimate . If it doesn't go to zero, that makes our parameter estimate biased, which is not at all what we want.
Control of plug-in bias?
The three different strategies for building efficient estimators that we're going to learn about differ only in the way that they ensure this term is eliminated. All of these methods eliminate the plug-in bias exactly without needing to make any additional assumptions about the initial plug-in estimate . We'll talk a lot more about that later.
Empirical Process
The term is known as the empirical process term because there is an entire field called empirical process theory that studies things that look exactly like . These creatures are called empirical processes because they are special kind of stochastic processes based on the empirical distribution .
We'll see there are two ways we can make sure this term is : sample splitting and Donsker conditions. We'll discuss what these are shortly but for both of them we will need to assume that where the norm is the norm . This is nothing but saying that the true mean-squared error of , viewed as a prediction of , goes to zero. Note is itself a random function (because comes from , which comes from the random data). In this notation we are not averaging over the variability of itself when we take the norm so therefore is itself a random variable and the convergence is in probability. We call this condition -consistency (of the estimated influence function).
-Consistency: and one of:
Use sample splitting
Estimate such that is in a Donsker class
This is the first restriction that we need to impose on the plug-in estimate to ensure we get an efficient estimator of . In fact, without this assumption, not only could our estimator be inefficient, it might not even be asymptotically normal.
You may wonder whether this -consistency condition is reasonable to assume. The truth is that in most cases it's very easy to satisfy! In other words, it's not even an assumption, it's just a required condition that we have to make sure we meet.
For example, when estimating the ATE in an observational study, we know the influence function depends on through the functions and . If you do a little bit of "limit algebra" with tools like Slutsky's theorem and the continuous mapping theorem you can quickly show that all that is needed for -consistency of is -consistency of and (and a uniform bound keeping away from 0, but a) since we already assume this for for identification, this is very reasonable and b) this is easy to enforce by truncating the output of the estimate). Why is that good? Well, a large number of commonly used machine learning algorithms have been shown to be nonparametrically -consistent (e.g. highly-adaptive lasso, nearest neighbors, deep learning, boosting, and random forests). So if we estimate and using any of those machine learning algorithms, or any cross-validated ensemble of them, then we know we satisfy the -consistency condition and we have nothing to worry about from the empirical process term: it will go to zero quickly in large samples as long as we also meet one of the two following criteria.
Control Via Sample Splitting
The simplest way to make sure this term goes away is to use sample splitting (also called cross-fitting or cross-estimation). The idea is to estimate all the parts of that go into the influence function using one sample and then to evaluate the estimator using another sample.
For example, when estimating the ATE in an observational study, we know the influence function depends on through the functions and . If we were using sample splitting, we'd split our sample in two, let's say into two datasets (1) and (2). The first of these we will use to estimate and , which we then take as fixed. We then evaluate the plug-in estimate using only the second sample: (in this case we don't need for the plug-in estimate). We can then reverse the roles of the two datasets to get and obtain our final estimate as the average of and .
If this sounds sort of like cross-validation to you, that's exactly right. It's the same idea and the same procedure. The only difference is that we're using the "validation sample" to get an estimate of the parameter instead of specifically using the validation sample to estimate the MSE of some prediction function.
Just as we do in cross-validation, this process can be extended to multiple () splits instead of just two. When we do this we use notation like or to denote the influence function and its components estimated using the all the data except for the th fold and we use to denote the set of indices that are included in the th fold.
A relatively brief proof shows that if we use sample splitting and we assume the -consistency condition on , then the empirical process term is indeed as desired. This is remarkable because, as we've already discussed, in most cases it's pretty easy to prove -consistency for . So all we need to do to ensure that the empirical process term goes away is to use sample splitting, something we can implement with a simple for loop in code.
Proof: sample splitting controls the empirical process term
Throughout this proof we'll be considering the random variable where is the empirical measure over the data in fold , which we'll denote . We'll start by computing the mean and variance of this random variable conditioned on having observed a fixed dataset comprising of all the folds except the th. By conditioning on , becomes the fixed function :
Now we apply Chebyshev's inequality, which generally quantifies the probability that a random variable takes a (de-meaned) value that's larger than its standard deviation: . Instead of using , though, we use , which gives
Now we can take the expectation on both sides (averaging over ) to get
Which by the definition of stochastic boundedness shows that
Here we've used the big-O notation for stochastic boundedness. This notation works the same way as the little-o but instead of meaning that the term converges in probability to 0 it means that the term is bounded in probability (i.e. the tails don't get too fat). You can read more about this in chapter 2 of vdV98 or in other sources. In the second-to-last equality we used the -consistency assumption to say that . In the last equality we used the fact that .
This shows that we've controlled the empirical process term that shows up in the estimate from the th fold, i.e. . Since this holds for all folds and the final estimate is the average of these estimates, the empirical process term for the full estimate is the average of the equivalent for the fold estimates. Since all of these are it follows that the empirical process term for the full estimate is also .
The only downside of using sample-splitting to control the empirical process term is that you might be afraid of some finite-sample bias that comes from effectively using less data. This should never be an issue in large samples, but may be of concern in small studies.
Control Via Donsker Conditions
The alternative to using sample splitting is to assume that our estimate of the influence function falls into something called a Donsker class. A Donsker class is just a family of functions that are not "too complicated". There are many examples, for instance all functions that are of bounded variation (think: bounded total "elevation gain" + "elevation loss" for a function of 1 variable) form a Donsker class. This example in particular is a very big class of functions, especially for a fixed bound that is large.
If is Donsker and -consistent, it follows immediately from an important result in empirical process theory (lemma 19.24 in vdV98) that . The proof of that requires more asymptotic statistics that I'd like to assume you already know, but if you're curious (and comfortable with the material in chapter 2 of vdV98), then by all means go ahead and read chapter 19 of vdV98!
So how do we make sure we satisfy the Donsker condition (i.e. make sure is in a Donsker class)? Well, thankfully there are theorems that show that Donsker properties are preserved through most algebraic operations (again, see vdV98 ch. 19). The upshot of that is that if we can estimate the components of that we need for in a way that guarantees they fall in Donsker classes, then will be Donsker. In our observational study ATE example, that means that whatever machine learning algorithms we use to learn the functions and need to always return functions that are in a known Donsker class if we want to be Donsker.
There are two major problems with this. Firstly, the vast majority of machine learning algorithms are not guaranteed to return learned functions that are in some Donsker class (though some, like highly-adaptive lasso, are). Secondly, for -consistency to hold at the same time as the Donsker condition, we must assume that the true influence function also falls into some Donsker class (technically the same one as our estimates, but since unions of Donsker classes are Donsker we can just join the two). Donsker classes are very often quite big so this isn't that crazy of an assumption to make. Nonetheless it's something to be aware of.
Overall, Donsker conditions are a less robust way of controlling the empirical process term relative to sample splitting because they impose stricter requirements on the algorithms you can use to estimate the components of and also because they imply a restriction on the model space . However, in small data settings these may be reasonable costs to pay to ensure asymptotically efficient inference without having to do sample splitting.
Second-Order Remainder
The term is known as the second-order remainder because, like the empirical process term, it can usually be shown to disappear at a "second-order" rate like or better under certain conditions. The difference is that these conditions are often specific to the exact parameter and model we're working with, unlike the empirical process term which we've seen can be bounded in a very general way. Therefore the most general condition we can impose on is that the estimate behaves in a way such that .
Depending on the problem, this may require us to be able to estimate regression functions (like and in our running example) at fast rates. This is a strong condition that we'll say more about below.
Second-Order Remainder is second order:
May require fast (e.g. ) -convergence of regression estimators
Example: ATE in Observational Study
For example, consider again the ATE in an observational study, or, to simplify things, just the conditional mean . We can now exactly compute the second-order remainder using the expression for the influence function we previously derived:
Derivation details
To get to the second-to-last equation we use the fact that . The last inequality comes via Cauchy-Schwarz and assumes is bounded away from 0.
The notation doesn't make it terribly clear, but the expectations and norms here are with respect to alone- we're not averaging over the randomness in the estimation of or (remember these come from , which is something we estimated from the data). One way to think of this is to imagine that we've used a separate sample to estimate and and these expectations are conditional on the (independent) data in that sample. As a consequence, is indeed a random variable.
Given the final expression we've arrived at, a set of sufficient conditions for is that and . This is because . We could also require that one of these goes faster and the other slower, as long as the product of the rates is .
Attaining Rates and the Highly Adaptive Lasso
Asking for an rate on the estimation of the functions and is much stronger than the consistency we required to control the empirical process term (that's just an requirement). For the latter, we just need that those functions go to their true values in the limit as we get more and more training data. For the former, we need that limiting behavior to happen fast enough. If the rates are too slow, we can't guarantee that the term gets small fast enough for the efficient central limit term to dominate in large samples. As a result, our estimator might not even have a normal sampling distribution, which would crush any chance we have at performing inference.
Without putting unrealistic smoothness conditions on the true functions and , it is very, very difficult to attain the required rate, even with a machine learning algorithm. In fact, there are some general theorems that show that attaining such a rate is impossible if we assume general high-dimensional function spaces without such smoothness conditions. This is called the curse of dimensionality.
The curse of dimensionality made efficient inference in observational studies difficult if not impossible in the general nonparametric model. The strategy in the past was to use a cross-validated ensemble of machine learning methods and pray that the true function was smooth or low-dimensional enough that one of these methods actually could attain the rate or better. Cross-validation is known to asymptotically select the best learner, which justifies this strategy as long as prayers are granted.
The highly-adaptive lasso (HAL) is a recent method for supervised learning that effectively solves this problem. Under non-restrictive assumptions, HAL can attain the rate (better, actually!). This is astounding. HAL still requires an assumption to be made on the regression function of interest (thus restricting the model space) but this assumption is much more believable than asking for low-dimensionality or smoothness. Specifically, HAL asks that the true regression function (e.g. ) is right-continuous with left limits (cadlag) with bounded variation norm. This norm can be arbitrarily large, as long as it is finite. But this is barely an assumption at all because it's difficult to imagine a real world scenario with a regression function that isn't cadlag with bounded variation norm. The genius of HAL and the trick to how it "breaks" the curse of dimensionality is that it places no restrictions on the local behavior the regression function (e.g. how wiggly/smooth it is) but instead restricts the global behavior (how much it can go up and down in total).
Double Robustness
In the observational study example we saw that the second-order remained could be controlled if the product of two rates is . This happens in several other estimation problems so there is a general name for the phenomenon. When the second-order remainder takes such a form, we say that the estimation problem is doubly robust.
The reason this term is appropriate is because we have two chances to completely cancel out the second order remainder term. For instance, consider the ATE observational study example, but now presume that is known (i.e. we're in an RCT). Then so the whole term is exactly 0. The same thing happens if we know .
Double robustness is a property of the estimation problem, not of any particular estimator. Some estimators that use both and (or equivalents for the estimation problem in question) are sometimes called "doubly robust", but it's most accurate to say that these estimators exploit double robustness to attain efficiency and asymptotic normality under certain conditions (e.g. rates on the regression estimates). Moreover there are estimation problems that may have triple, quadruple, etc. robustness, or only single-robustness (i.e. only a single function needs to be estimated), etc.
Double robustness was historically more important than it is today because parametric models were used more often to estimate nuisance components. It's rarely if ever the case that a parametric model can capture the truth, but at least if you have two (or more) chances to be right then there's a little more hope. On the other hand, double robustness says nothing about what happens when both models are wrong, even if one or the other is still "close" enough in some sense. Since that's more realistically the case with parametric models, some have argued that the entire premise is somewhat meaningless. Either way, it's rarely justifiable to not to leverage modern, flexible estimators like HAL in current practice, so assuming consistency of nuisance components is no longer a matter of hope. This makes the entire question of double robustness more of a moot point than it has ever been.
Summary
By analyzing the naive plug-in estimator, we managed to come to the following decomposition of estimation error that shows us exactly what conditions must be satisfied in order for our plug-in to be efficient.
Specifically, we need the following three terms to be :
Plug-In Bias:
Empirical Process:
Second-Order Remainder:
And we came up with the following conditions to ensure that these terms do indeed go away:
Control of plug-in bias?
Empirical process is if we have -Consistency: and one of:
Use sample splitting
Estimate such that it is in a Donsker class
Requires -convergence of regression estimators (e.g. )
Second-Order Remainder is second order:
May require fast (e.g. ) -consistency of regression estimators
Effectively, we have found reliable ways to control both the empirical process and second-order remainder terms, as long as a) the components of our plug-in are modeled with powerful machine learning techniques that converge quickly to the truth as data are added and b) we use sample splitting or algorithms that guarantee their estimates are not too flexible.
The only thing that we're missing, therefore, are conditions or methods that control the plug-in bias. There are three ways that have been proposed over the years to handle this and that's exactly what we're going to discuss in the subsequent sections. Once this is handled, we've got an estimator that has the efficient influence function and therefore attains the minimum possible asymptotic variance!
The conditions required for control of the empirical process and 2nd order remainder terms are all totally attainable in practice, meaning that we can build efficient estimators for most estimation problems without making any scientifically meaningful statistical assumptions. Remember, however, that we usually do need scientifically meaningful causal assumptions in order to link our statistical parameter to a causal parameter of interest! These are separate, though, and apply uniformly regardless of how we choose to estimate the statistical parameter.